我們已經從ComfyUI 搭建了我們第一個文生圖的工作流,但節點其中有很多名詞,讓我們一知半解。 我們就從ComfyUI工作流,來說明穩定擴散模型,了解原理以後,對以後擴展我們工作流有很有幫助
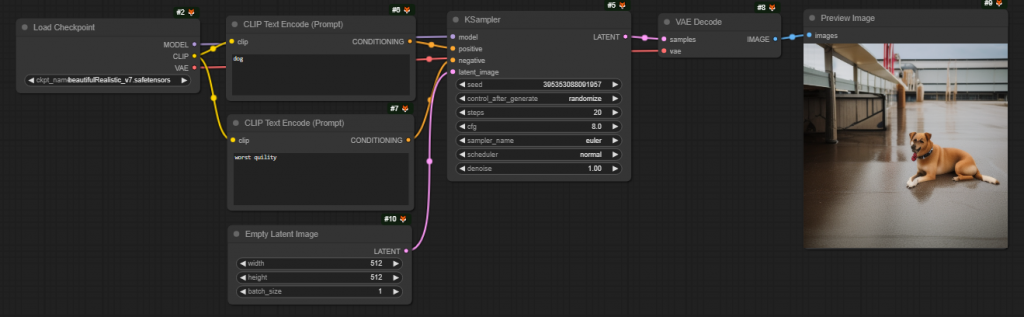
擴散模型現在是生成影像的首選模型。由於擴散模型它是一種從原始的文本對應到圖像的模型,並允許透過提示來調節影像生成,如下圖所示,而在這些文本條件擴散模型中,穩定擴散模型因其開源特性而最為著名。
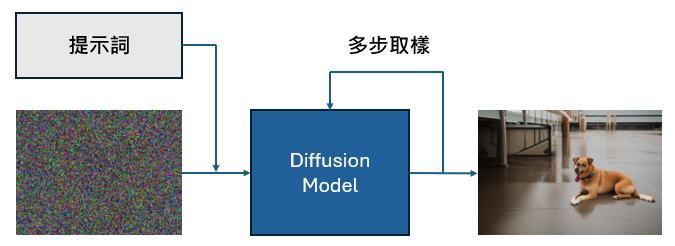
我們將把穩定擴散模型分解為組成它的三個主要部分:
我們可以從文生圖 comfyui workflow 看到這三個主要部分
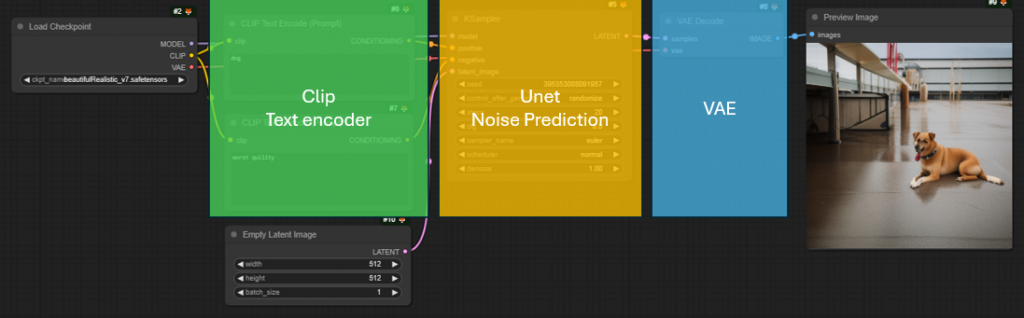
文字編碼器:
文字編碼器都是一個大型的預訓練 Transformer 語言模型。 Stable Diffusion 使用CLIP的預訓練文字編碼器部分進行文字編碼,使用者也可以使用其他預先訓練的語言轉換器模型,例如 T5 和 BERT。。文字編碼器將提示詞作為輸入並輸出多維的 token embedding,之後可以在Unet作為提示影響Unet預測結果。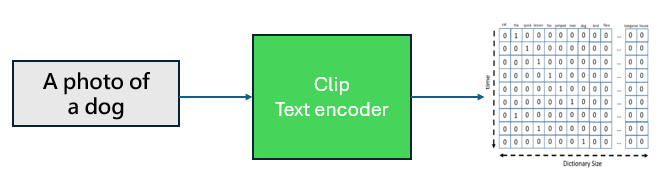
UNet噪音預測模型:
在文生圖的流程,在 UNet 之前,會準備一個潛空間表示的噪聲影像,以文字編碼器的token embedding提示為條件,訓練好的UNet會進行多步採樣過程, 嘗試預測噪聲影像,文字條件與生成影像的彼此對應關係,生成新的還原影像。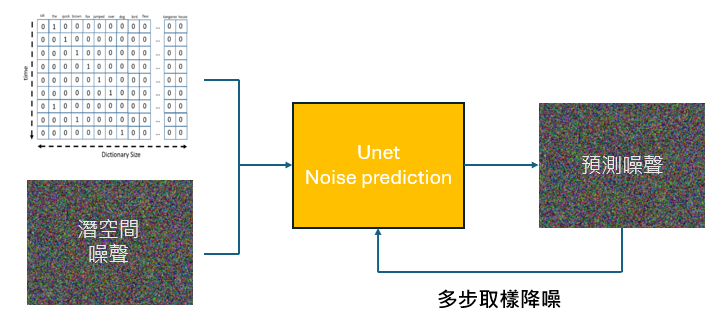
變分自動編碼器-解碼器模型(VAE):
由於 UNet 是在潛空間進行預測,我們要把預測結果還原成人眼可以識別的圖像,就會透過VAE進行潛空間跟像素空間的轉換,還原生成出我們想要的影像。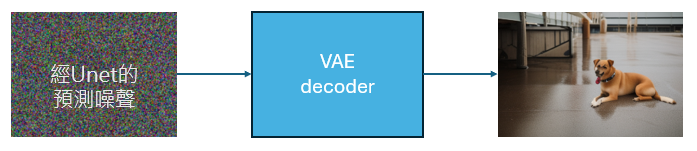
透過這樣的分解,我們就可以清楚了解在Comfyui工作流節點的用法跟連結運作方式,未來就可以很容易在原本的工作流添加新的節點,進行圖生圖或放大圖片的工作流。


 iThome鐵人賽
iThome鐵人賽